
유형
- 트라이(트리)
특징
입력되는 문자열이 집합 S에 포함되어 있는 문자열 중 적어도 하나의 접두사인가? 라는 질문에 해답을 구하는 것이 바로 Trie 구조의 특징이라고 할 수 있다.
집합 S에 포함된 문자열이 {”BAND”, “BANANA”} 인 상황을 예로 들면 아래 다이어그램과 같다.
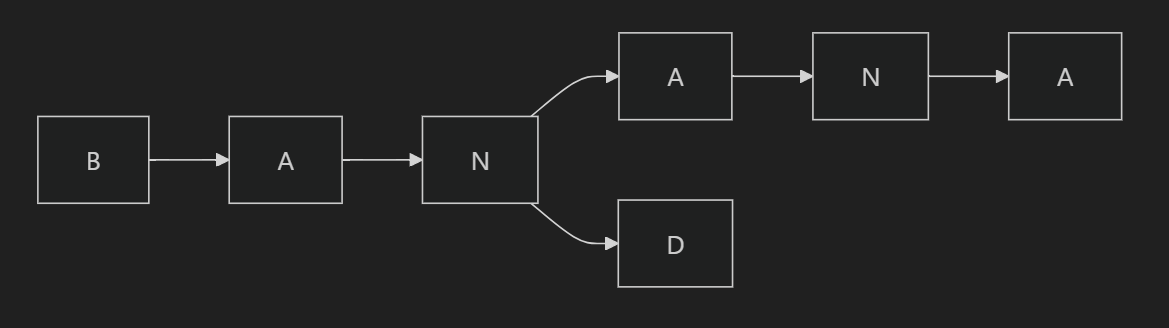
아래는 위 다이어그램의 Mermaid 코드이다.
graph LR
B --> A --> N --> A2[A]
N-->D
A2 --> N2[N]
N2 --> A3[A]
이제 접두사인지 궁금한 입력된 문자열들에 대해 다이어그램 기반으로 접두사인지 파악하는 예시이다.
- 입력된 문자열이 B, BA, BAN 인 경우 : 2개 문자열 모두의 접두사이다.
- 입력된 문자열이 BANDED 인 경우 : Trie 자료구조 상 D는 Child로 E를 가지지 않으므로 조건에 부합하지 않는다.
집합 S의 문자열들을 위 다이어그램과 같이 저장해두면 문제에서 원하는 탐색을 진행할 수 있음을 알았다. 그렇다면 위와 같은 방식으로 문자열들을 저장하려면 어떻게 구현해야할까?
1. 문자 한 글자(char)를 하나의 노드 값으로 취급한다.
2. 하나의 노드는 여러개의 자식 노드를 가진다.
3. 이미 특정 글자(char)로 자식노드가 존재한다면, 새로 자식노드를 생성하지 않는다.
- 1,2번 : 노드 는 자신의 key값과, 자식들의 목록을 자식의 key값을 식별 할 수 있는 상태로 들고 있어야한다. 루트 노드는 null key값과 집합 내 모든 문자열들의 첫 글자를 자식노드로 갖는다.
- 3번 : 어떤 노드의 자식 노드들을 Map과 같은 자료구조로 관리해야한다.
코드
static class TrieNode {
Character key;
Map<Character, TrieNode> child;
public TrieNode(Character key) {
this.key = key;
child = new HashMap<>();
}
public void addChild(char c) {
this.child.put(c, new TrieNode(c));
}
public TrieNode getChild(char c) {
if (this.child.containsKey(c)) {
return this.child.get(c);
}
return null;
}
}
static class Trie {
TrieNode head;
public Trie() {
head = new TrieNode(null);
}
public void insert(String str) {
TrieNode cur = this.head;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (cur.getChild(c) == null) {
cur.addChild(c);
cur = cur.getChild(c);
} else
cur = cur.getChild(c);
}
}
public boolean prefixSearch(String str) {
TrieNode cur = this.head;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (cur.getChild(c) == null)
return false;
else
cur = cur.getChild(c);
}
return true;
}
}
static void solve() throws Exception {
int n = scan.nextInt();
int m = scan.nextInt();
Trie trie = new Trie();
for (int i = 0; i < n; i++) {
trie.insert(scan.nextLine());
}
int count = 0;
for (int i = 0; i < m; i++) {
count += trie.prefixSearch(scan.nextLine()) ? 1 : 0;
}
sb.append(count);
}
유형
- 트라이(트리)
특징
입력되는 문자열이 집합 S에 포함되어 있는 문자열 중 적어도 하나의 접두사인가? 라는 질문에 해답을 구하는 것이 바로 Trie 구조의 특징이라고 할 수 있다.
집합 S에 포함된 문자열이 {”BAND”, “BANANA”} 인 상황을 예로 들면 아래 다이어그램과 같다.
아래는 위 다이어그램의 Mermaid 코드이다.
graph LR
B --> A --> N --> A2[A]
N-->D
A2 --> N2[N]
N2 --> A3[A]
이제 접두사인지 궁금한 입력된 문자열들에 대해 다이어그램 기반으로 접두사인지 파악하는 예시이다.
- 입력된 문자열이 B, BA, BAN 인 경우 : 2개 문자열 모두의 접두사이다.
- 입력된 문자열이 BANDED 인 경우 : Trie 자료구조 상 D는 Child로 E를 가지지 않으므로 조건에 부합하지 않는다.
집합 S의 문자열들을 위 다이어그램과 같이 저장해두면 문제에서 원하는 탐색을 진행할 수 있음을 알았다. 그렇다면 위와 같은 방식으로 문자열들을 저장하려면 어떻게 구현해야할까?
1. 문자 한 글자(char)를 하나의 노드 값으로 취급한다.
2. 하나의 노드는 여러개의 자식 노드를 가진다.
3. 이미 특정 글자(char)로 자식노드가 존재한다면, 새로 자식노드를 생성하지 않는다.
- 1,2번 : 노드 는 자신의 key값과, 자식들의 목록을 자식의 key값을 식별 할 수 있는 상태로 들고 있어야한다. 루트 노드는 null key값과 집합 내 모든 문자열들의 첫 글자를 자식노드로 갖는다.
- 3번 : 어떤 노드의 자식 노드들을 Map과 같은 자료구조로 관리해야한다.
코드
static class TrieNode {
Character key;
Map<Character, TrieNode> child;
public TrieNode(Character key) {
this.key = key;
child = new HashMap<>();
}
public void addChild(char c) {
this.child.put(c, new TrieNode(c));
}
public TrieNode getChild(char c) {
if (this.child.containsKey(c)) {
return this.child.get(c);
}
return null;
}
}
static class Trie {
TrieNode head;
public Trie() {
head = new TrieNode(null);
}
public void insert(String str) {
TrieNode cur = this.head;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (cur.getChild(c) == null) {
cur.addChild(c);
cur = cur.getChild(c);
} else
cur = cur.getChild(c);
}
}
public boolean prefixSearch(String str) {
TrieNode cur = this.head;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (cur.getChild(c) == null)
return false;
else
cur = cur.getChild(c);
}
return true;
}
}
static void solve() throws Exception {
int n = scan.nextInt();
int m = scan.nextInt();
Trie trie = new Trie();
for (int i = 0; i < n; i++) {
trie.insert(scan.nextLine());
}
int count = 0;
for (int i = 0; i < m; i++) {
count += trie.prefixSearch(scan.nextLine()) ? 1 : 0;
}
sb.append(count);
}